Unraveling the Effects: Collider Adjustments in Logistic Regression
By Ken Koon Wong in r R collider logistic regression simulation plogis
August 22, 2023
Simulating a binary dataset, coupled with an understanding of the logit link and the linear formula, is truly fascinating! However, we must exercise caution regarding our adjustments, as they can potentially divert us from the true findings. I advocate for transparency in Directed Acyclic Graphs (DAGs) and emphasize the sequence: causal model -> estimator -> estimand.
A few weeks ago, with the guidance of Alec Wong and a new acquaintance, Jose Luis Cañadas, I wrote a blog post about model adjustment involving a collider. Initially, I intended to utilize binary data. However, Alec astutely observed inaccuracies in both my simulations and models, steering me in the correct direction. This revision seeks to address those inaccuracies for the sake of completeness. Every day is truly a learning experience! I’m deeply grateful to both Alec and Jose for their invaluable insights, which have enriched my understanding of the captivating world of Statistics.
Objectives
- Simulate data featuring binary exposures/treatments, covariates (including a collider), and outcomes.
- Employ logistic regression to determine the accurate exposure/treatment coefficient.
- Turning all nodes binary
Simulation
library(tidyverse)
library(DT)
library(broom)
{
set.seed(1)
n <- 1000
w <- rnorm(n)
z <- rnorm(n)
s <- rnorm(n)
x <- rbinom(n,1,plogis(-0.5+0.2*w+0.2*z))
y <- rbinom(n,1,plogis(-2+2*x+0.2*w+0.2*z+0.2*s))
collider <- -5 + -5*x+ -0.2*s + rnorm(n,0,0.5)
# not including unobserved_conf
df <- tibble(w=w,z=z,x=x,y=y,collider=collider,s=s)
}
datatable(df)
DAG
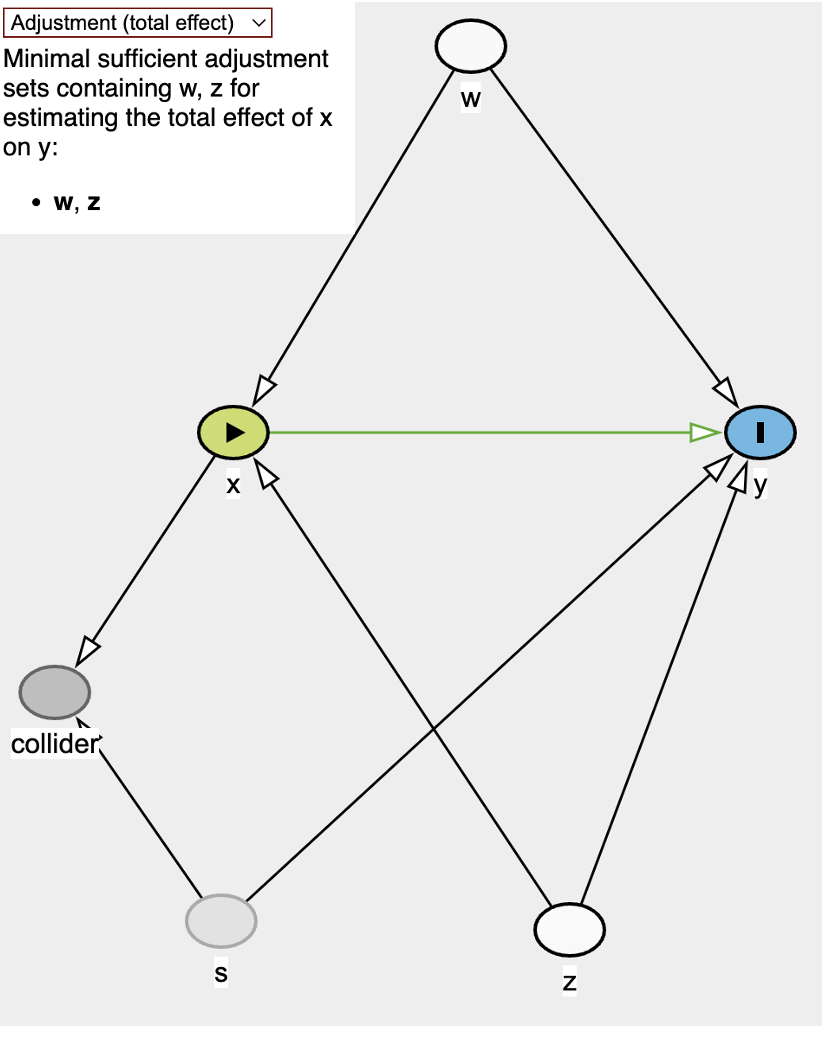
Nodes:
w,s, andzare confounders. Though, note thatsis unobservedxis exposure/treatmentyis outcomecollideris collider.
It looks like the minimal adjustment would be just w and z.
Adjusting for w and z only ✅
model <- glm(y~x+w+z,data=df,family="binomial")
summary(model)
##
## Call:
## glm(formula = y ~ x + w + z, family = "binomial", data = df)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.7782 -0.5652 -0.4497 0.9673 2.3566
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -2.11550 0.13229 -15.991 < 2e-16 ***
## x 2.16374 0.16667 12.982 < 2e-16 ***
## w 0.26724 0.08058 3.317 0.000911 ***
## z 0.22723 0.07883 2.883 0.003944 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 1170.48 on 999 degrees of freedom
## Residual deviance: 943.62 on 996 degrees of freedom
## AIC: 951.62
##
## Number of Fisher Scoring iterations: 4
The true intercept is -2 and our model has -2.1155.
The true coefficient of x is 2 and our model has 2.1637352.
Not too bad. Adjusting the minimal nodes did the trick. Note that we didn’t even have to adjust for s. Pretty cool! 😎
Adjusting for w, z, and collider ❌
model_col <- glm(y~x+w+z+collider,data=df,family="binomial")
summary(model_col)
##
## Call:
## glm(formula = y ~ x + w + z + collider, family = "binomial",
## data = df)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.8287 -0.5738 -0.4469 0.9094 2.3815
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -3.70414 0.75863 -4.883 1.05e-06 ***
## x 0.60378 0.74205 0.814 0.41584
## w 0.25745 0.08092 3.181 0.00147 **
## z 0.23114 0.07921 2.918 0.00352 **
## collider -0.31467 0.14693 -2.142 0.03222 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 1170.5 on 999 degrees of freedom
## Residual deviance: 939.0 on 995 degrees of freedom
## AIC: 949
##
## Number of Fisher Scoring iterations: 4
The true intercept is -2 and our 2nd model has -3.7041443.
The true coefficient of x is 2 and our 2nd model has 0.6037755.
Not very good. 🤣 Maybe the 95% confidence interval might include the true estimate. Let’s check it out.
confint(model_col)
## Waiting for profiling to be done...
## 2.5 % 97.5 %
## (Intercept) -5.20894145 -2.23173654
## x -0.84961777 2.06247208
## w 0.09973181 0.41732051
## z 0.07679436 0.38766046
## collider -0.60438394 -0.02774385
Barely. Technically, the coefficient shouldn’t really be interpreted as anything meaningful since the 95% CI contains 0 which means the estimate could decrease or increase the log odds of y. Yup, not helpful 😆
What if We Adjust ALL, If s is Observed?
model_all <- glm(y~x+w+z+collider+s,data=df,family="binomial")
summary(model_all)
##
## Call:
## glm(formula = y ~ x + w + z + collider + s, family = "binomial",
## data = df)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.7833 -0.5816 -0.4439 0.9015 2.5101
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -3.04677 0.83248 -3.660 0.000252 ***
## x 1.28154 0.82550 1.552 0.120556
## w 0.25439 0.08142 3.124 0.001782 **
## z 0.23076 0.07938 2.907 0.003646 **
## collider -0.18096 0.16300 -1.110 0.266915
## s 0.16869 0.08921 1.891 0.058621 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 1170.48 on 999 degrees of freedom
## Residual deviance: 935.39 on 994 degrees of freedom
## AIC: 947.39
##
## Number of Fisher Scoring iterations: 5
The true intercept is -2 and our model has -3.0467671.
The true coefficient of x is 2 and our model has 1.2815422.
OK, maybe the x coefficient got a little better but statistics indicates it crosses zero. Still not good enough. 😱
Full On Binary Dataset
{
set.seed(2)
n <- 1000
w <- rbinom(n,1,0.5)
z <- rbinom(n,1,0.5)
s <- rbinom(n,1,0.5)
x <- rbinom(n,1,plogis(-0.5+0.2*w+0.2*z))
y <- rbinom(n,1,plogis(-2+2*x+0.2*w+0.2*z+0.2*s))
collider <- -5 + -5*x+ -0.2*s + rnorm(n,0,0.5)
# not including unobserved_conf
df <- tibble(w=w,z=z,x=x,y=y,collider=collider,s=s)
}
model_bin <- glm(y ~ x + z + w, data=df, family = "binomial")
summary(model_bin)
##
## Call:
## glm(formula = y ~ x + z + w, family = "binomial", data = df)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.2951 -0.6175 -0.5594 1.0641 2.0243
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -1.9110 0.1601 -11.936 <2e-16 ***
## x 1.8329 0.1522 12.039 <2e-16 ***
## z 0.1355 0.1497 0.905 0.366
## w 0.2150 0.1497 1.437 0.151
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 1238.2 on 999 degrees of freedom
## Residual deviance: 1071.5 on 996 degrees of freedom
## AIC: 1079.5
##
## Number of Fisher Scoring iterations: 4
The true intercept is -2 and our 2nd model has -1.910973.
The true coefficient of x is 2 and our 2nd model has 1.8328523.
Notice that estimates aren’t as precise as the previous dataset where w and z were continuous variables. I found that small tweaks of parental/ancestral nodes with binary data and the x and y intercepts would change the estimates dramatically. Very intersting!
Let’s Test Out With collider
model_bin_col <- glm(y~x+w+z+collider,data=df,family="binomial")
summary(model_bin_col)
##
## Call:
## glm(formula = y ~ x + w + z + collider, family = "binomial",
## data = df)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.3622 -0.6205 -0.5549 1.0865 2.0783
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -2.5416 0.7698 -3.301 0.000962 ***
## x 1.2227 0.7409 1.650 0.098881 .
## w 0.2158 0.1497 1.441 0.149518
## z 0.1414 0.1500 0.943 0.345885
## collider -0.1230 0.1465 -0.840 0.401188
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 1238.2 on 999 degrees of freedom
## Residual deviance: 1070.8 on 995 degrees of freedom
## AIC: 1080.8
##
## Number of Fisher Scoring iterations: 4
The true intercept is -2 and our 2nd model has -1.910973.
The true coefficient of x is 2 and our 2nd model has 1.8328523.
Wow, increase in intercept and decrease in x coefficient. Not good!
Comparison of all models 📊
df_model <- model |>
tidy() |>
mutate(model = "z + w") |>
relocate("model") |>
add_row(model_col |>
tidy() |>
mutate(model = "z + w + collider")) |>
add_row(model_all |>
tidy() |>
mutate(model = "z + w + collider + s")) |>
add_row(model_bin |>
tidy() |>
mutate(model = "all binary: z + w")) |>
add_row(model_bin_col |>
tidy() |>
mutate(model = "all binary: z + w + collider"))
df_model |>
ggplot(aes(x=term,y=estimate,ymin=estimate-std.error,ymax=estimate+std.error)) +
geom_point() +
geom_linerange() +
geom_hline(aes(yintercept = -2),color="red", alpha = 0.5) +
geom_hline(aes(yintercept = 2),color="blue", alpha = 0.5) +
facet_wrap(.~model) +
theme_minimal() +
theme(axis.text.x = element_text(hjust = 1, angle = 45))

Putting them all together, our first model z+w and all binary z+w models accurately estimated x coefficient and its intercept. Hurray!
Lessons learnt
inverse logit function(plogis) is used to convert the linear equation to probability- adjusting for
collideris still not a good thing. Now maybe Jose may use Full-Luxury Bayesian Stats to work this miracle again, looking forward!
Acknowledgement
- Thanks again Alec and Jose!
If you like this article:
- please feel free to send me a comment or visit my other blogs
- please feel free to follow me on twitter, GitHub or Mastodon
- if you would like collaborate please feel free to contact me
- Posted on:
- August 22, 2023
- Length:
- 8 minute read, 1543 words
- Categories:
- r R collider logistic regression simulation plogis