Mandell O Mandell, Please Grant Me Some Insight!
By Ken Koon Wong in R r mandell learning NLP text mining tidytext pdftools infectious disease
September 24, 2022
TL;DR Bring a textbook to life by Using a simple Natural Language Processing method (Ngram) to guide focused reading and build a robust differential diagnosis

Introduction
What would you do if you encountered a clinical case with quite a few nuance symptoms? How do you know which article to look at to build a differential diagnosis? It is helpful to have ample experience to guide clinical reasoning. What if you have not encountered such a clinical case? The next step is usually reaching out to more experienced colleagues or mentors. What if we could also reach out to our buddy old pal, textbook? But how to read the book more efficiently, or perhaps smartly?
For example, we have a 50-year-old male who presented with a productive cough and diarrhea for three weeks. CT chest showed ground glass opacities. CT abdomen/pelvis showed splenomegaly and mesenteric lymphadenopathy. No risk factor for HIV. He has a pet bird. What would your differential diagnosis be? Psittacosis crossed any Infectious Disease providers’ minds, but what other conditions may have similar symptoms?
Let’s take ground glass, diarrhea, splenomegaly, lymphadenopathy, and bird as our five keywords. How can we quickly scan through Mandell and show us the chapters of interest?
Thought Process
- List all mandell pdf files
- Create an empty dataframe & Mine Texts
- Save dataframe for future use
- Create function to search for keywords
- Look at what we have here
- Opportunity for improvement / Future potential
List all mandell pdf files
# list all pdf, remember to change '/path/to/your/mandell'
files <- list.files(path = "/path/to/your/mandell", pattern = "pdf$")
pdf$ means look for files that end with pdf
Create an empty dataframe & Mine Texts

library(tidyverse)
library(pdftools)
library(tidytext)
# Create an empty dataframe - see comment 2.1
full_bigram <- tibble(title = as.character(""), chapter = as.integer(""), page = as.integer(""), bigram = as.character(""))
# Mine Text Section
## For loop to create a ngram - see comment on 'what is an ngram?'
## since there are 324 files/chapters, we are basically parsing and adding on to our dataframe file by file
for (i in (1:324)) {
# use pdftools package to parse its texts into a dataframe - see comment 2.21
# please remember to change /path/to/your/mandell
pdf <- pdf_text(paste0("/path/to/your/mandell",files[i])) %>%
as_tibble()
# Extract the title of the chapter by its filename
title <- files[i] %>%
str_extract(pattern = "(?<=[[:digit:]]_).*(?=.pdf)") # comment 2.22
# Get Chapter Number
num <- files[i] %>%
str_extract(pattern = "^[[:digit:]]+(?=_)") # comment 2.23
# Text Mining
text <- pdf %>%
mutate(title = title, # insert title variable above
chapter = as.integer(num), # insert num variable above as integer
page = row_number()) %>% # insert row number which is page num, see comment 2.24
# using tidytext::unnest_tokens to create a bigram
unnest_tokens(bigram, value, token = "ngrams", n = 2) %>%
# separate the bigram into 2 columns
separate(bigram, c("word1","word2"), sep = " ") %>%
# remove stop words in both columns (word1, word2), comment 2.26
filter(!word1 %in% stop_words$word) %>%
filter(!word2 %in% stop_words$word) %>%
# merge those 2 columns back
unite(bigram, word1, word2, sep = " ")
full_bigram <- bind_rows(full_bigram, text) # comment 2.25
}
2.1 Create an empty tibble dataframe with column names of title, chapter, page, bigram, with its respective data type
2.21 Parse all the pdf
2.22 Regular Expression "(?<=[[:digit:]]_).*(?=.pdf)"means extract everything that is sandwiched between a number and .pdffor example picture
2.23 Regular Expression ^[[:digit:]]+(?=_)" means ^ == start with, [[:digit:]] == all numbers, + == one or more, (?=_) == precede _
2.24 pdttools::pdf_text parse each pdf page as a row, hence we will insert row_number() as our page number
2.25 example of our bigram
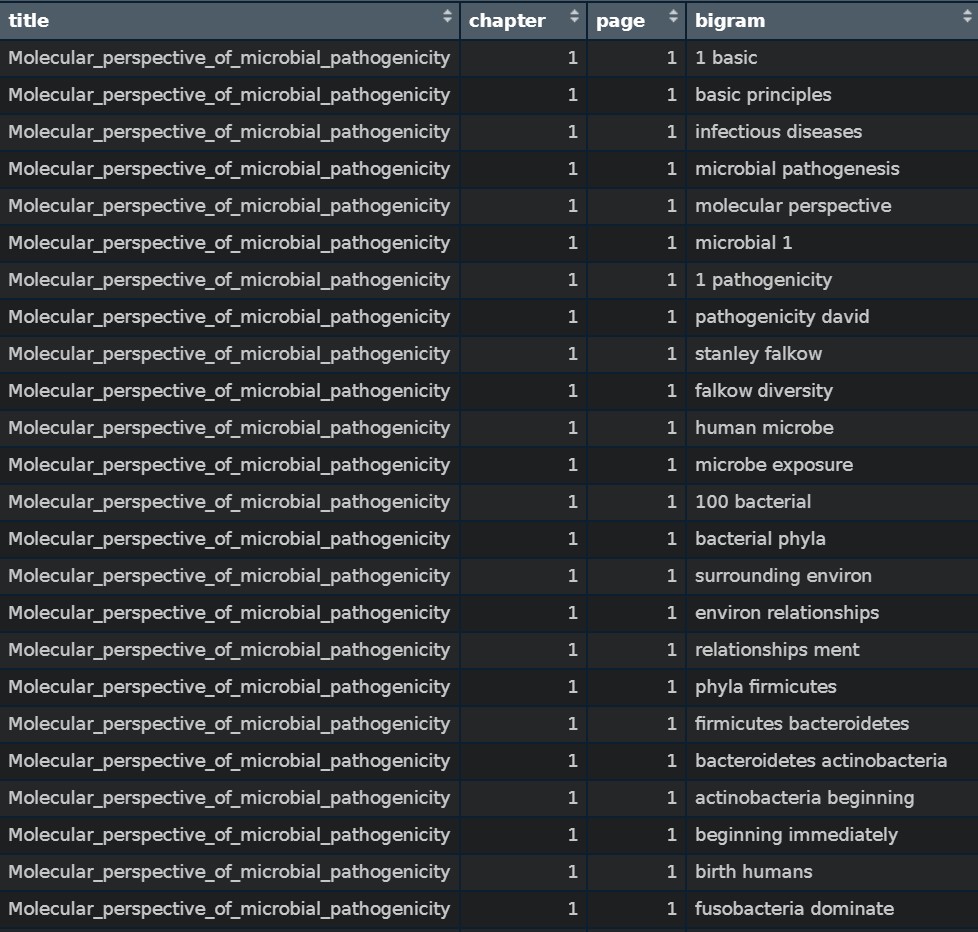
2.26 Stop words examples

What is an ngram?
According to
Wikipedia, an n-gram is a contiguous sequence of n items from a given sample of text or speech, where N is a number.
For example, if a phrase Mandell O Mandell, Please Grant Me Some Insight! will have the following 2-gram/bigram: Mandell O, O Mandell, Mandell Please, Please Grant, Grant Me, Me Some, Some Insight. For best practice, make sure the letters are all lower case.
Save dataframe for future use
save(full_bigram, file = "mandell_bigram.Rdata")
Save full_bigram dataframe as file mandell_bigram.Rdata in your working directory
Create function to search for keywords
library(tidyverse)
library(tidytext)
# load data
load(file = "mandell_bigram.Rdata")
# create a find function - comment 3.1
find <- function(a,b,c,d,e,ngram=bigram,data=full_bigram){
# uses rlang check out https://rlang.r-lib.org/reference/enquo.html
a1 <- enquo(a)
b1 <- enquo(b)
c1 <- enquo(c)
d1 <- enquo(d)
e1 <- enquo(e)
ngram <- enquo(ngram)
data <- data
find2 <- data %>%
drop_na() %>%
# group by chapter
group_by(chapter) %>%
# filter out any ROWS that have ANY of these 5 keywords
filter(str_detect(!! ngram, paste0(!! a1,"|",!! b1,"|",!! c1,"|",!! d1,"|",!! e1))) %>%
# filter out any CHAPTERS that have ALL of the 5 keywords
filter(
any(str_detect(!! ngram, !! a1)) &
any(str_detect(!! ngram, !! b1)) &
any(str_detect(!! ngram, !! c1)) &
any(str_detect(!! ngram, !! d1)) &
any(str_detect(!! ngram, !! e1))) %>%
# count how many times each chapter mentions the 5 keywords
# the higher the frequency, the more we need to check out its insight
# btw, count will automatically add a column 'n' with its frequency
count(title, chapter, !! ngram)
return(find2)
}
# This is where you would insert in your keywords, see comment 4.1
a <- "ground glas"
b <- "bird"
c <- "lymph"
d <- "diarrhe"
e <- "spleno"
# execute the function
result2 <- find(a,b,c,d,e)
result <- result2 %>%
group_by(chapter) %>%
# sum the total of 'n' (count from the function)
mutate(total = sum(n)) %>%
arrange(desc(total))
4.1 Ideally, you want to maximize return of Regular Expression search. If you would like to know more about Regular Expression ( RegEx), please click here.
Look at what we have here
# view the result without all the noise by filtering to just the title
result %>%
ungroup() %>%
arrange(desc(total)) %>%
distinct(title, .keep_all = TRUE) %>%
view()
 Wow, I wouldn’t have thought about toxoplasma or MAI! Intersting result. But are they reliable? We would have to look into it a bit more. Please note that we have used
Wow, I wouldn’t have thought about toxoplasma or MAI! Intersting result. But are they reliable? We would have to look into it a bit more. Please note that we have used distinct to shorten the result. So it is only showing distinct chapter/title and its total arranged descendingly.
Let’s look at Toxoplamsa and MAI in details
toxo <-
result %>%
filter(str_detect(title, "Toxo"))
toxo %>% view()
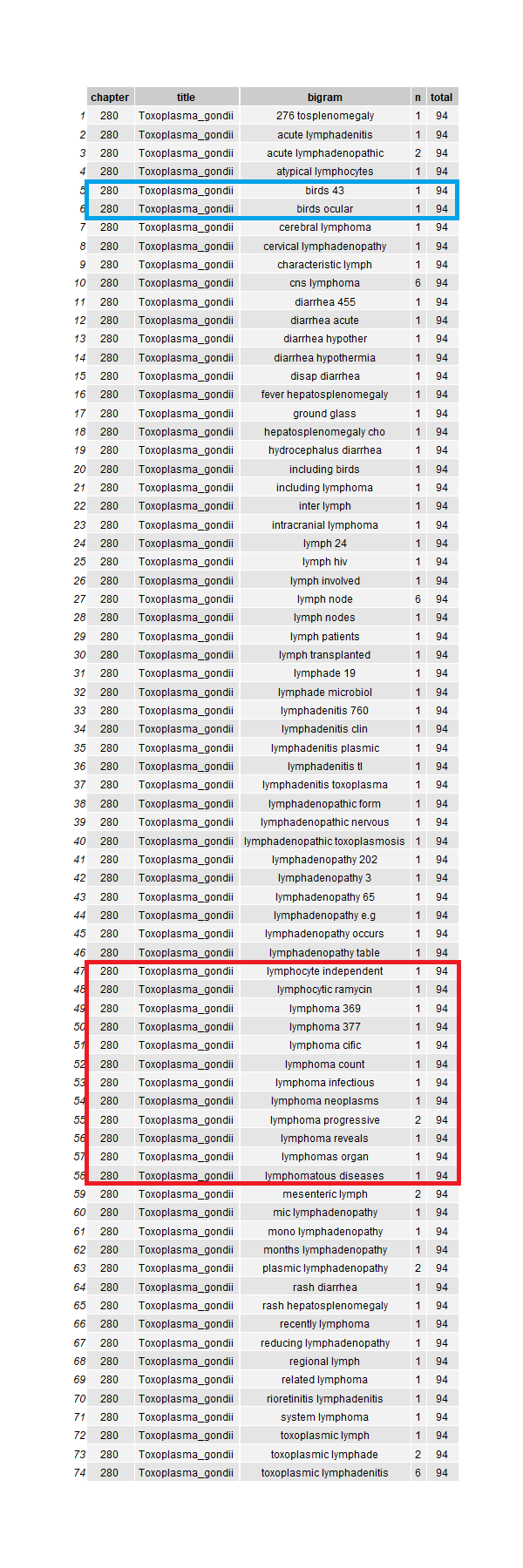
Looks legit. Upon further reading the chapter, these five keywords should also prompt this condition. I don’t remember birds being a host for toxoplasma. This creates more questions, but I take it as an excellent opportunity to look further into its references and, of course, WHAT KIND OF BIRD !?!
Observe some words containing lymph such as lymphoma were also captured. Have to be mindful of this.
mai <-
result %>%
filter(str_detect(title, "Myco"))
mai %>% view()
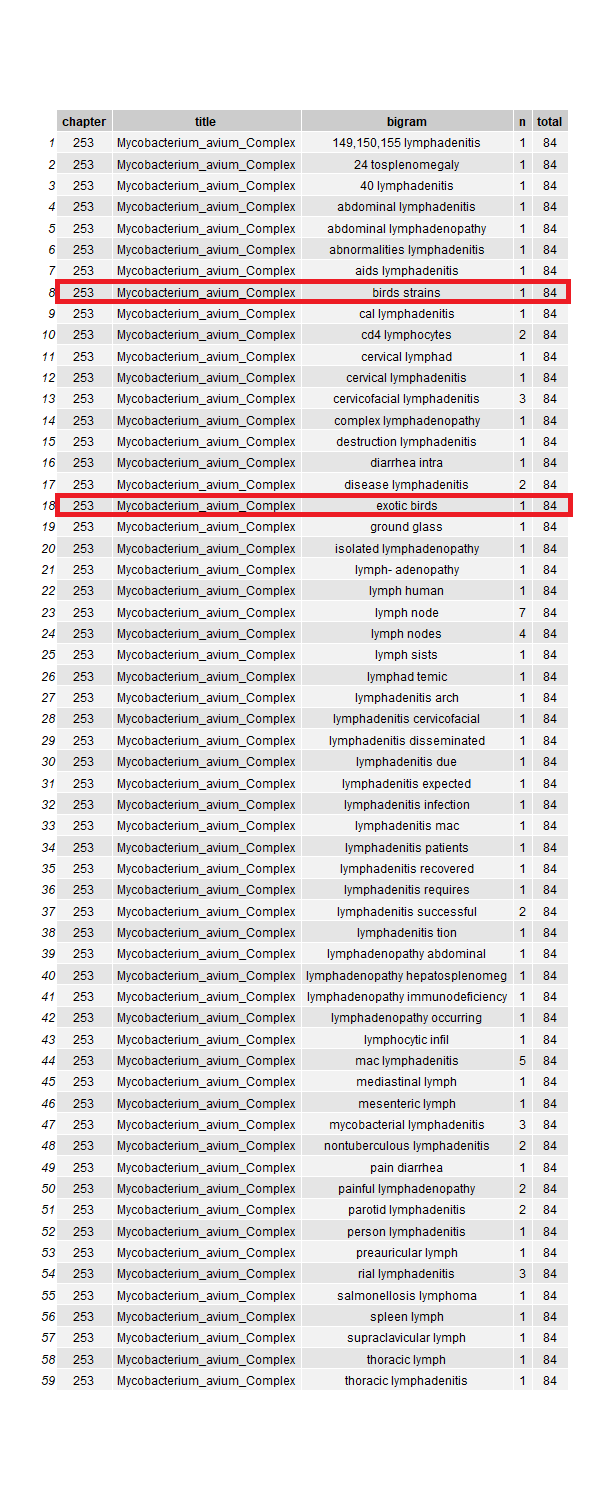
Now this is interesting. Observe that the bigram showed exotic birds and bird stain. How curious. Looking at the actualy text, it was actually referring to hypersentivity pneumonitis and the construct of the bigram bird stain was entire from a different paragraph but the same line. This is one of the limitation of using pdf to create ngram.

Something that is more interesting is that the pdf I used to extract words was an older edition. When I looked at the most recent Mandell edition, exotic bird is no longer included as part of the risk factor for hypersensitivity pneumonitis. I’m loving this! In just short period of time, one can make different connections and also appreciate the difference between edition of a textbook!
Opportunity for improvement / Future potential
- Imagine you have ngrams of all available case reports, case series, systemic review etc. That would be very helpful for differential diagnosis building. Can be possible with pubmed API and perhaps ever growing text/topic modelling database
- what if you have bigram of different textbooks (e.g., rheum, pulm, radiology etc). What a robust ddx we will be able to build
- Scrape the website instead of pdf to have a more accurate ngram as we will not have the
bird stainproblem - Add marginal probability/frequency of all of the buzzwords to assess marginal contribution
Conclusion/Lessons Learnt
Phew, that was intense!
- text mining with
tidytext - extracting texts using
pdftools - removing
stopwordsto improve relevant text extraction - NLP can be used to enhance learning and building a robust differential diagnosis
If you like this article:
- please feel free to send me a comment or visit my other blogs
- please feel free to follow me on twitter or GitHub
- if you would like collaborate please feel free to contact me
- Posted on:
- September 24, 2022
- Length:
- 7 minute read, 1425 words
- Categories:
- R r mandell learning NLP text mining tidytext pdftools infectious disease